Linux C语言程序设计
- 基础:数据类型,数据表现形式,运算符,表达式,语句, 三大设计结构
- 核心:数组,函数,指针
- 进阶:构造类型,预处理,库文件,标准文件流,位运算
- 高级:数据结构,算法,工程管理,工程调试,版本控制
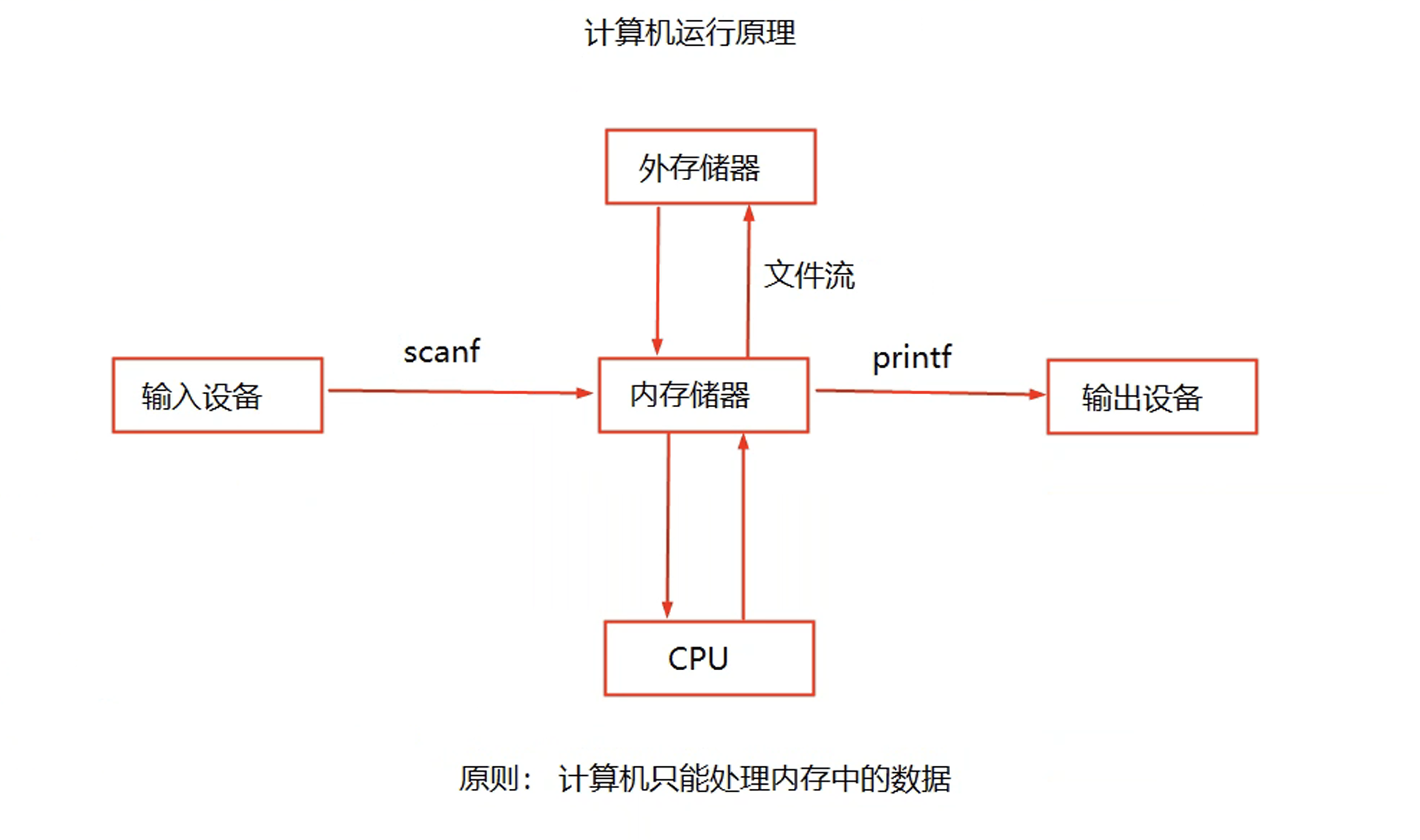
C语言基础
- 编译过程:预处理、编译、汇编、链接
- printf 格式化列表:要求用一组 " " 括起来 格式化列表中可出现的内容:
- 普通字符:格式化列表中的普通字符是原样输出的,
- 转义字符:(\加上特定的字符) \n \t \0 \r
- 格式化符:(%加上特定的字符) %c %d %e %s
C语言编码风格
- 常用缩进书写格式
- 有足够的注释
- 有合适的空行
- {}对齐
- 函数体内采用分层缩进和模块化的书写方式
- 不把多条语句写在程序的同一行上
- 命名:变量或函数命名要尽可能包含更多含义,但不能太长,可采用_和缩写来命名
c语言数据类型
- 基本数据类型 数值类型:int,float,double 字符类型:char
- 构造数据类型 数组、结构体(struct)、联合体(union)、枚举(enum)
- 指针类型
- 空值类型:void
- 定义类型:typedef
进制转换
| 进制名称 | 英文缩写 | 数字符号集合 | 进位规则 | 常见前缀/后缀 |
|---|---|---|---|---|
| 十进制 | DEC | 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 | 逢十进一 | 无 / D |
| 二进制 | BIN | 0, 1 | 逢二进一 | 0b / B |
| 八进制 | OCT | 0, 1, 2, 3, 4, 5, 6, 7 | 逢八进一 | 0 / O |
| 十六进制 | HEX | 0-9, A(10), B(11), C(12), D(13), E(14), F(15) | 逢十六进一 | 0x / H |
- 16转8: 先转换为二进制,从后往前看,每4位一组,每组转换成8进制,然后拼接起来。
- 8进制转16: 先转换为二进制,每3位一组,每组转换成16进制,然后拼接起来。
数据表现形式
常量
- 整型常量
- 浮点型常量
- 字符型常量
- 符号常量
变量
不同类型数据在内存中的储存方式
整型数据
- 在内存中是以补码方式存储的
- 原码: 将最高位作为符号位(0 表示正,1表示负),其他位代表了数据绝对值
- 反码: 如果是正数,反码就是原码,如果是负数,符号位不变,其余为按位取反
- 补码: 如果是正数,补码就是原码,如果是负数, 反码 + 1
- 格式控制符
int 整型:%d short 整型:%hd, h代表half,即一半的存储字节 long 整型:%ld long long 整型:%lld 显示不同进制的前缀: %#o、 %#x
浮点型数据
- (在内存中以二进制小数表示)以指数方式存储,数据分为指数与小数部分 符号位(1) + 指数位(8 /11) + 尾数(23 / 52)
- 浮点型数据先分别将整数部分与小数部分转换为二进制数据。
- 将转换后的数据以科学计数法的方式表示
- 根据数据的正负,确认最高位(符号位),然后将指数 + 指数偏移量(127 / 1023) 转换为8位数据 / 11位数据,将科学计数法表示的尾数部分(.以后)放置在最后的 23/52位
注意: 浮点型数据在内存中存储的是一个近似值,因为有些浮点型数据无法用有限数位来表示。
- 面试题: 浮点型数据和 0 怎么比较?
定义一个极小的正数作为误差阈值(通常称为 Epsilon),只要浮点数的绝对值小于这个阈值,我们就认为它“等于” 0。
- 字符型数据:
在内存中并不是存储字符本身,而是存储字符的ASCII码值。
不同数据类型混合运算
类型转换方式:
- 隐式类型转换: 编译系统自动转化: 转换规则: 低优先级类型 —> 高优先级转换
- 强制类型转化: 程序员自行完成转换。 转换语法:(目标类型) 待转换数据/表达式;
printf 格式说明符
整型格式
| 格式说明符 | 功能描述 | 输出示例 | 适用场景 / 备注 |
|---|---|---|---|
%d / %i | 有符号十进制整数 | 123、-456 | 最常用的 int 类型输出;%i 在输入时可自动识别八/十六进制 |
%u | 无符号十进制整数 | 456、65535 | 适用于 unsigned int,不输出负号 |
%o | 无符号八进制整数 | 710、177777 | 默认不带前导0;加 # 修饰符(%#o)可自动补前导0 |
%x / %X | 无符号十六进制整数 | 2af、2AF | 字母分别为小写/大写;加 # 修饰符(%#x)可自动补前导 0x |
%hhd / %hhu | 有符号/无符号 char | 65、255 | char 类型专用,避免类型提升导致的输出异常 |
%hd / %hu | 有符号/无符号 short | 32767、65535 | short 类型专用 |
%ld / %lu | 有符号/无符号 long | 123456789 | long 类型专用 |
%lld / %llu | 有符号/无符号 long long | 9223... (超大数) | long long 类型专用,支持64位及以上超大范围整数 |
浮点型格式
| 格式说明符 | 功能描述 | 输出示例 | 适用场景 / 备注 |
|---|---|---|---|
%f / %F | 十进制小数形式 | 3.141593 | 默认保留 6 位小数,自动四舍五入;%F 会大写输出 INF/NAN |
%lf | 双精度浮点数 | 3.1415926535 | double 类型专用(C99及以上标准),精度高于 %f |
%e / %E | 科学计数法 | 1.23e+02 | 指数部分用小写 e 或大写 E,适用于超大/超小数值 |
%g / %G | 自动选择最短格式 | 123.456 | 自动在 %f 和 %e 之间选择较短的表示,并去掉末尾无意义的 0 |
%a / %A | 十六进制浮点数 | 0x1.92p+1 | C99 新增,用十六进制精确表示浮点数,避免十进制转换的精度损失 |
%Lf | 长双精度浮点数 | 3.14159265... | long double 类型专用,支持最高精度的浮点数输出 |
字符与字符串格式
| 格式说明符 | 功能描述 | 输出示例 | 适用场景 / 备注 |
|---|---|---|---|
%c | 单个字符 | A、\n | 输出 char 类型的单个字符,支持转义字符 |
%C | 宽字符 | 中、の | 适用于 wchar_t 类型,输出多字节宽字符 |
%s | 字符串 | Hello World | 输出以 \0 结尾的 char* 字符串,遇 \0 自动停止 |
%S | 宽字符串 | 你好世界 | 适用于 wchar_t* 类型,输出多字节宽字符串 |
特殊用途格式
| 格式说明符 | 功能描述 | 输出示例 | 适用场景 / 备注 |
|---|---|---|---|
%p | 指针地址 | 0x7ffe... | 输出 void* 类型的内存地址,标准十六进制形式 |
%n | 已输出字符计数 | (无直接输出) | 将当前已输出的字符总数写入对应的 int* 参数中,不产生任何显示内容 |
%% | 输出百分号 | % | 转义格式,用于在输出中打印 % 符号,避免被识别为格式说明符 |
%m | 输出系统错误信息 | No such file... | GNU 编译器扩展,自动输出当前 errno 对应的系统错误描述 |
宽度与精度
- %md:指定最小宽度为 m,不足用空格填充。
- %.nf:浮点数保留 n 位小数。
- %.ns:字符串最多输出前 n 个字符。
C 语言 I/O 缓冲区的“进与出”
| 问题场景 | 涉及函数 | 根本原因 | 最佳解决方案 |
|---|---|---|---|
printf 后接死循环无输出 | printf (输出) | 输出缓冲区未刷新。 内容卡在内存里,没遇到换行或程序结束,导致没来得及显示。 | 在字符串末尾加上换行符 \n(或者手动调用 fflush(stdout)) |
连续 scanf 第二个被跳过 | scanf (输入) | 输入缓冲区有残留。 前一次输入留下的换行符 \n 被后面的 %c 当作有效字符读走了。 | 在 %c 前加一个空格 " %c"(或者用 getchar() 提前吃掉换行符) |
查漏补缺
表达式优先级问题
| 优先级梯队 | 包含运算符 | 结合性 | 说明 |
|---|---|---|---|
| 第1梯队 (最高) | () [] . -> | 左→右 | 括号、数组下标、成员访问 |
| 第2梯队 | ! ~ ++ -- * & sizeof | 右→左 | 单目运算符(逻辑非、指针、自增等) |
| 第3梯队 | * / % | 左→右 | 算术运算(乘除模) |
| 第4梯队 | + - | 左→右 | 算术运算(加减) |
| 第5梯队 | << >> | 左→右 | 移位运算 |
| 第6梯队 | < <= > >= | 左→右 | 关系运算(比较大小) |
| 第7梯队 | == != | 左→右 | 关系运算(比较相等) |
| 第8梯队 | & | 左→右 | 位运算(按位与) |
| 第9梯队 | ^ | 左→右 | 位运算(按位异或) |
| 第10梯队 | | | 左→右 | 位运算(按位或) |
| 第11梯队 | && | 左→右 | 逻辑与 |
| 第12梯队 | || | 左→右 | 逻辑或 |
| 第13梯队 | ? : | 右→左 | 条件运算符(三目) |
| 第14梯队 | = += -= 等 | 右→左 | 赋值运算 |
| 第15梯队 (最低) | , | 左→右 | 逗号运算符 |
整型运算核心
数据的底层存储法则(截断与溢出) 在计算机底层,数据最终都是以二进制比特序列的形式存在的。 截断机制:当把一个较大范围的数据类型(如 32 位整数)赋值给较小范围的类型(如 8 位字符)时,编译器会直接截取低位二进制存入,高位部分被丢弃。 溢出与重解释:如果截断后的二进制序列超出了目标类型的表达范围,计算机会按照目标类型的编码规则(有符号数通常采用补码)重新解释这段二进制,从而得到一个“面目全非”的数值。
运算与传参的预处理法则(整型提升) 为了保证 CPU 的运算效率,C 语言规定在表达式运算或作为可变参数(如 printf 的参数)传递时,所有小于 int 长度的整型(如 char、short)都必须先转换为 int(或 unsigned int)。这个转换过程称为“整型提升”,其核心规则如下: 有符号数的符号扩展:如果原类型是有符号的且值为负数(最高位是 1),提升时高位全部补 1;如果值为正数,高位全部补 0。这保证了提升前后的数值大小不变。 无符号数的零扩展:如果原类型是无符号的,无论数值是多少,提升时高位一律补 0。
格式化输出的解释法则(格式符决定视角) printf 等输出函数本身并不知道传入变量的真实类型,它完全依赖程序员提供的“格式控制符”来解读内存中的二进制数据。 有符号解读(如 %d):函数会将传入二进制序列的最高位视为符号位。如果是 1,则将其视为负数(补码)进行解析。 无符号解读(如 %u):函数会忽略符号位的概念,将传入的所有二进制位全部视为数值位,直接计算其代表的正整数大小。
混合运算的类型对齐法则(算术转换) 当不同长度的整数参与同一个数学运算时,编译器会按照“向长度更长、精度更高的类型对齐”的原则,自动将短类型转换为长类型,再进行计算。
- 有符号与无符号的碰撞:当有符号整数与无符号整数进行运算时,如果它们的长度相同(例如都是 32 位),有符号数会被强制转换为无符号数参与运算。这意味着原本的负数会被当作一个极大的正数来处理,这往往是导致逻辑判断出现严重偏差的隐形陷阱。
#include <stdio.h>
int main() {
// 初始化变量
signed char a = -1;
unsigned char b = 255;
short c = -1;
// 运算与输出
printf("1. %d\n", a + b); // 254
printf("2. %u\n", (char)b); // 2^32 - 1
printf("3. %d\n", (unsigned short)c); // 65535
// 0000 0000 0000 0001
// 1111 1111 1111 1110
// 1111 1111 1111 1111 2^16-1 = 65535
return 0;
}- 存储看补码,运算看提升,输出看格式。
数组
一维数组常见的陷阱
- 索引越界
- 牢记数组下标从 0 开始,到 长度-1 结束。
- 循环条件严格使用 i < 数组长度。
- 数组传参时的“长度消失”
- 数组传参时,数组名会自动转换成指针,指针的 sizeof 为指针的大小,而不是数组的长度。
- 在传递的时候需要额外增加一个长度的变量
- 返回局部数组的地址
- 函数返回局部变量的地址,函数结束后,局部变量会被回收,返回的地址会指向一个不存在的地址。
- 解决方法:
- 创建一个全局变量,将局部变量的值赋给全局变量,返回全局变量的地址。
- 使用 malloc 实现动态内存分配,返回分配的指针,注意释放内存。
- 数组名是地址常量,不能整体赋值
- 使用 memcpy 等内存拷贝函数。
- 字符数组使用 strcpy 函数。
- 未初始化导致“垃圾值”
- 定义时立即初始化。
int arr[10] = {0};可以将所有元素初始化为0。 - 全局数组或静态数组(static)会被自动初始化为0。
二维数组常见陷阱
- 定义时不能省略列数
- 在定义并初始化二维数组时,可以省略行数,但绝对不能省略列数。编译器需要知道列数来计算内存偏移,以正确访问元素。
函数传参时,列数必须明确
混淆行指针与二级指针
行指针是什么? 列指针是什么?
字符数组与字符串的专属陷阱
- 忘记字符串结束符 \0
- 在字符数组中,字符串的结束符必须用 \0 来结束。如果没有结束符,那么字符串将无法被正确处理。
- 缓冲区溢出
- 字符数组的大小必须足够大,以容纳字符串。如果字符串的长度超过字符数组的大小,那么字符串将无法被正确处理。
- 注意: strncpy 在截断时不会自动添加 \0,需要手动添加。
常用字符数组函数
- strcpy:将源字符串复制到目标字符串。
- strncpy:将源字符串复制到目标字符串,最多复制 n 个字符。
- strcat:将源字符串追加到目标字符串的末尾。
- strncat:将源字符串追加到目标字符串的末尾,最多追加 n 个字符。
- strlen:返回字符串的长度。
- strcmp:比较两个字符串。
- strncmp:比较两个字符串,最多比较 n 个字符。
- strstr:在源字符串中查找子字符串。
- strchr:在源字符串中查找字符。
- strrchr:在源字符串中从末尾开始查找字符。
- strspn: 该函数返回 str1 中第一个不在字符串 str2 中出现的字符下标。
- strcpan: 该函数返回 str1 开头连续都不含字符串 str2 中字符的字符数。
函数
| 常见陷阱 | 错误表现 | 正确做法 |
|---|---|---|
| 数组传参 | 在函数内用 sizeof(arr) 算长度 | 将数组长度作为额外参数传入 |
| 修改实参 | 直接传变量,在函数内修改形参 | 传递变量的地址(指针) |
| 函数声明 | 不写参数类型,依赖编译器默认 | 使用完整原型声明(含参数类型) |
| 返回值 | 非 void 函数漏写 return | 开启 -Werror=return-type 强制检查 |
指针
| 分类 | 踩坑点 | 错误示例 | 问题原因 | 正确写法 |
|---|---|---|---|---|
| 野指针 | 未初始化直接使用 | int *p; *p = 10; | 指针未指向合法地址 | int a; int *p = &a; |
| 空指针 | NULL 解引用 | int *p = NULL; *p = 1; | 访问空地址 | 使用前判断 p != NULL |
| 越界访问 | 指针超过数组范围 | *(p + 10) | 访问非法内存 | 保证范围合法 |
| 返回局部变量地址 | 返回栈区地址 | return &a; | 函数结束后地址失效 | 使用 static 或 malloc |
| 内存泄漏 | malloc 后不释放 | malloc(...) | 堆内存无法回收 | free(p) |
| 重复释放 | free 两次 | free(p); free(p); | 堆损坏 | free(p); p=NULL; |
| 释放后继续使用 | free 后访问 | free(p); *p=1; | 地址已无效 | 释放后置 NULL |
| sizeof 误区 | sizeof(指针) | sizeof(p) | 得到的是地址大小 | sizeof(*p) |
| 数组退化 | 数组当指针用 | sizeof(arr) | 数组和指针不同 | 注意函数参数退化 |
| 指针步长 | 指针+1误解 | p+1 | 实际加 sizeof(type) | 理解类型步长 |
| 指针运算错误 | 重复乘 sizeof | p + sizeof(int) | 指针已自动偏移 | p + 1 |
| 优先级问题 | *p++ | *p++ | 实际是 *(p++) | 修改值用 (*p)++ |
| 二级指针 | *pp 与 **pp | *pp | 少解引用一级 | 根据层级取值 |
| 字符串常量修改 | 修改只读区 | "abc"[0]='A' | 常量区不可写 | char str[]="abc" |
| 指针类型不匹配 | int* 赋给 char* | p = c; | 步长与解析不同 | 类型保持一致 |
| memset误区 | memset赋1 | memset(arr,1,...) | 按字节填充 | 仅适合 0/-1 |
| 函数参数修改失败 | 修改形参指针 | p=NULL; | 传值拷贝 | 使用二级指针 |
| 数组名误解 | arr 与 &arr | arr+1 | 类型不同 | 理解数组指针 |
| 指针自增 | 后置++问题 | str[j++] | 先使用再自增 | 注意执行顺序 |
| 悬空指针 | 指向已释放内存 | free后仍保存地址 | 地址已失效 | p=NULL |
| 表达式 | 实际含义 |
|---|---|
*p++ | *(p++) |
(*p)++ | 当前值自增 |
arr | 首元素地址 |
&arr | 整个数组地址 |
sizeof(arr) | 整个数组大小 |
sizeof(p) | 指针大小 |
char *s = "abc" | 常量字符串 |
char s[] = "abc" | 可修改数组 |