项目代码展示
- 项目部署方法, 已发GitHub, 项目地址github地址
使用技术
- python正则匹配
- Beautifulsoup4库
- xpath解析
正则匹配
- 和JavaScript语言匹配方式类似
- 使用前需导入
re包 - 有几种正则匹配的方法:match, search, compile, findall, finditer
re.match(a, b, c)
- 三个参数: 匹配的规则, 要匹配的字符串, 匹配方式
- 它是从字符串的第一个位置进行匹配如果满足使用
.span()方法可以返回它所在的索引位置, 如果不满足则返回None 返回结果.groups()返回一个包含所有小组的字符串的元组, 使用group(num)方法可以返回一个包含对应值的元组(从1开始)
re.search(a, b, c)
- 也是三个参数, 与上面相同
- 获取元组方法也相同, 唯一的不同点就是, search不是从一开始进行匹配, 而是如果字符串中包含所要匹配的内容, 则返回第一个匹配成功的
- 注意只返回一个不是多个
re.sub(a, b, c, d, e)
- 执行
替换操作 a正则中的模式字符串b要替换的字符串, 也可以是一个函数c原始字符串d匹配后替换的最大次数, 默认是0表示全部匹配替换e匹配模式, 数字形式
re.compile(a, b)
- 用来编译正则表达式, 供match和search这两个函数使用
- 如果使用的是match方法 在获取匹配的字符时使用group方法获取参数可以省略不写也可以写0
- group方法参数的数值与你所写的正则表达式元组数有关
- start, end, span方法都是返回匹配字符在原字符串中所在的索引位置
findall(a, b, c, d)
- 参数分别表示: 正则表达式, 匹配的字符串, 指定匹配的起始位置, 结束位置
- 返回满足条件的所有子串, 列表的形式, 如不则返回空列表
- 如果由有元组则返回满足元组规则的字符 可进行遍历
finditer(a, b, c)
- 参数分别为: 匹配规则, 匹配的字符串, 匹配模式
- 和findall方法类似, 返回值使用迭代器方式返回使用
for in方法
re.split(a, b, c, d)
- 按照匹配规则将匹配的字符串进行分隔以列表的形式返回
- 参数分别为: 匹配规则, 匹配字符,
切割次数默认为0, 不限制次数, 匹配模式
正则表达式修饰符
re.I是匹配时大小写不敏感re.L做本地化识别re.S使. 匹配包括换行在内的所有字符re.M多行匹配影响^$re.U根据Unicode字符集解析字符. 这个标志影响 \w, \W, \b, \B.re.X该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解.
xPath方法
- 使用之前先安装好lxml库
pip i lxml - xPath使用路径表达式在XML文档中进行导航
- 可以对本地的html文件进行解析也可以直接对html字符串进行解析
Xpath常用的规则
nodename选取所有的子节点/选取当前节点下的子节点//选取当前节点的子孙节点.选取当前节点..选取当前节点的父节点@选取属性
本地展示
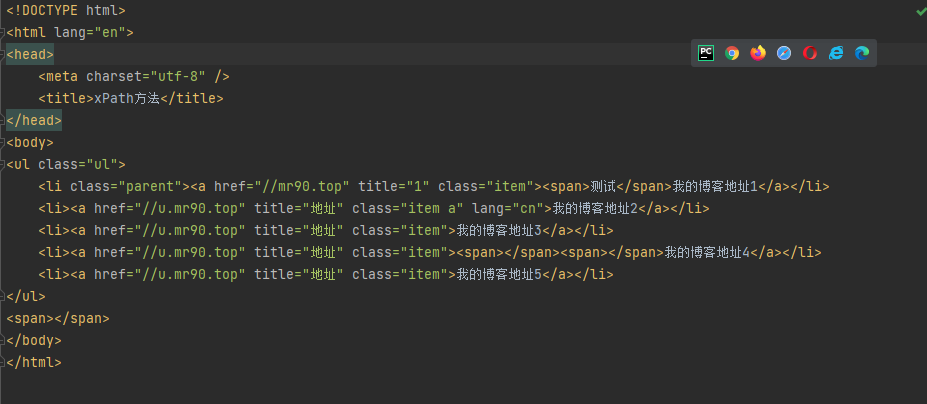
- 第一种使用
etree.parse方法解析本地
# coding= utf-8
from lxml import etree
html = etree.parse('./index.html',etree.HTMLParser())
print(etree.tostring(html))- 第二种方法使用
etree.HTML方法
# coding= utf-8
from lxml import etree
fp = open('./index.html', 'rb')
html = fp.read().decode('utf-8')
selector = etree.HTML(html) #etree.HTML(源码) 识别为可被xpath解析的对象
print(selector)- 匹配所有的节点 使用
//*规则匹配 - 匹配所有指定的节点使用
//节点名称 - 匹配所有的子节点将//换成
/ - 获取父节点属性值的方法
../@属性名 - 属性匹配可以使用
@属性名的方法 - 文本获取两种方法
/text()和//text(), 区别第一种直接获取文本, 第二种要获取换行时产生的特殊字符 - 属性获取使用
/@href获取 - 获取属性中包含多个值的情况 属性多值匹配
contains()方法 - 多属性匹配, 使用and运算符 和contains方法搭配使用
xPath运算符
- 除号和取余特殊, 其他的都与基本运算符一直
- 除号使用
div比如8 div 4 - 取余则是
mod比如1 mod 2 - 还有表示并列和或者的
and和or
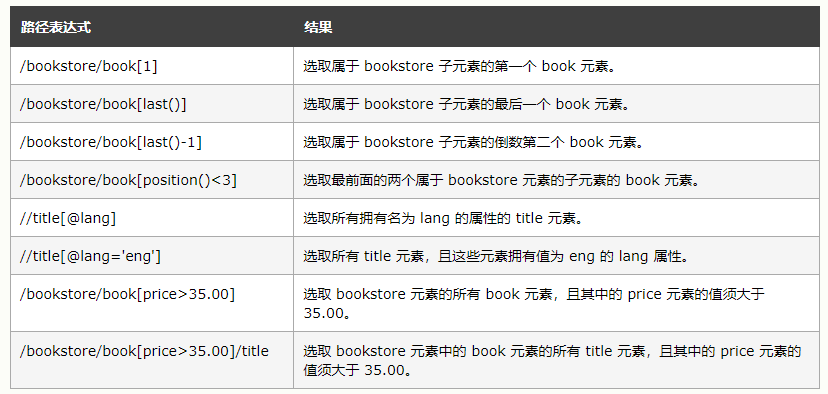
按序选择
- xPath内置了100多种函数方法, 具体参考【xPath函数】
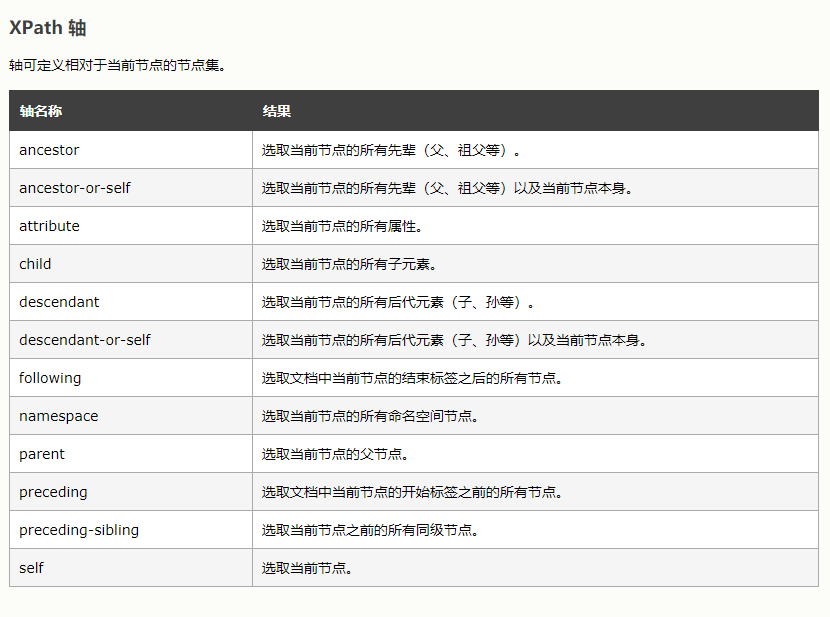
节点轴选择
- 获取当前节点所有子元素的
a节点的href属性值child::a/@href - 获取当前节点的指定元素的属性值
attribute:: 属性名 - 获取当前节点的所有的子元素
child::* - 获取当前节点 的所有属性的属性值
attribute::* - 获取当前节点所有子节点
child::node() - 获取当前元素所有文本子节点
child::text() - 获取当前元素的所有父辈为li元素的节点(包括当前元素)
ancestor-or-self:: 元素
演示代码
# coding= utf-8
from lxml import etree
# fp = open('./index.html', 'rb')
# html = fp.read().decode('utf-8') #.decode('gbk')
# selector = etree.HTML(html) #etree.HTML(源码) 识别为可被xpath解析的对象
# print(selector)
html = etree.parse('./index.html',etree.HTMLParser())
# print(etree.tostring(html).decode('utf-8'))
all_node = html.xpath('//*') # 所有节点的获取 //*
part_node = html.xpath('//li') # 部分节点 格式://节点名
child_node = html.xpath('//li/a') # 匹配子节点
parent_node = html.xpath('//a[@href="//ryanuo.cc"]/../@class') # 获取父节点属性值的方法 ../@属性名
attrs_node = html.xpath('//a[contains(@class,"a")]/text()') # 获取属性中包含多个值的情况 属性多值匹配 contains()方法
# 按序获取
first_node = html.xpath('//li[1]/a/text()') # 获取第一个
last_node = html.xpath('//li[last()]//text()') # 获取最后一个节点
front_node = html.xpath('//li[position()<3]//text()') # 获取前两个节点
end_ndoe = html.xpath('//li[last()-2]//text()') # 获取到数第三个节点
# 轴节点
child_node_z = html.xpath('//li[position()<2]/child::a/@href') # 获取当前节点所有子元素的a节点的href属性值
attribute_node = html.xpath('//li[2]//attribute::lang') # 获取当前节点的指定元素的属性值
all_child_node = html.xpath('//ul/li[last()-1]//child::*') # 获取当前节点的所有的文本节点
all_attrs_node = html.xpath('//li[1]/a/attribute::*') # 获取当前节点 的所有属性的属性值
all_child_text_node = html.xpath('//li[1]//child::text()') # 获取当前节点所有文本子节点
all_child_node_node = html.xpath('//li[1]/a/child::node()') # 获取当前节点所有子元素
ancestor_self = html.xpath('//a[@title="1"]/../ancestor-or-self::li') # 获取当前元素的所有父辈为li元素的节点(包括当前元素)
print(ancestor_self)Beautifulsoup4使用
Beautiful Soup自动将输入文档转换为Unicode编码, 输出文档转换为utf-8编码- 使用前安装
pip install beautifulsoup4 - 引入
from bs4 import Beautifulsoup4
获取内容
- 标签有两个重要的属性name, attrs
- 文本内容的获取有三种方法
.string方法返回一个迭代器.text方法返回节点文本.get_text()方法返回节点文本
## 获取标题对象
print(soup.title) # <title>xPath方法</title>
# 获取标题内容
print(soup.title.string) # 返回迭代器
print(soup.title.text)
print(soup.title.get_text())
print(soup.find('title').get_text())- 通过上下级获得对象
# print(soup.title.parent) # 返回父节点包括父节点中的内容
print(soup.li.child) # Node
print(soup.li.children) # 返回一个迭代器获取第一个li标签
print(soup.li.get_text()) # 匹配到第一个,返回所有节点的文本信息
print(soup.find('li').text)
# 获取ul的子标签们 (空行也看成了一个children)
print(soup.ul.children)
for index, item in enumerate(soup.ul.children):
print(index, item)获取元素的属性
- 使用
.属性名的方法, 但是只能获取到一个 - 使用
元素.attrs['属性名']的方法返回的时一个列表 - 如果使用两次
soup.元素第一次获取的是匹配到的第一个元素, 第二次是匹配到的第二个元素
获取多个元素
- find方法获取一个元素
- find_all获取多个元素, 可以加上
limit来达到限制个数的问题,recursive = True寻找子孙 ;recursive = False只找子 - 多层级查找 find_all返回的是一个列表 可以遍历该列表再次使用find方法或者find_all方法 进行元素的获取
通过指定的属性, 获取对象
- id和class选择器, class比较特殊, 因为是关键字 在使用class时改成
class_
print(soup.find(id='a'))
print(soup.find('a', id='a'))
print(soup.find_all('a', id='a')) # 可以使用下标查询
# class是关键字 要这么写class_
print('class1', soup.find_all('a', class_='a'))
print('class2', soup.find_all('a', attrs={'class': 'item'})) # 更通用
print('class3', soup.find_all('a', attrs={'class': 'item', 'id': 'a'})) # 多条件使用函数作为参数, 返回元素
def judgeTilte1(t):
if t == 'a':
return True
print(soup.find_all(class_=judgeTilte1))- 根据长度来判断
# 判断长度
import re # 正则表达式
reg = re.compile("item")
def judgeTilte2(t):
# 返回长度为5,且包含'item'的t参数
return len(str(t)) == 5 and bool(re.search(reg, t))
print(soup.find_all(class_=judgeTilte2))可以使用css选择器
- select方法返回的都是一个列表
- 可以通过标签名查找, 属性查找, 标签+类名+id, 组合查找
Python中BeautifulSoup库的用法python beautiful soup库的超详细用法python 爬虫 提取文本之BeautifulSoup详细用法